Configuration and Capabilities
We decided to use popular and mature Lucene library instead of developing our own engine and reach same pit falls as the DNN standard search. Lucene comes with lots of features and advanced syntax capabilities. We only integrated a handful of these which are the most popular and have been requested by our customers. These options are used to tweak the behavior of the search engine to achieve all kinds of setups.
Autocomplete Options Count

This option allows selecting the number of options the autocomplete feature should display at a maximum. The options are built from the content that is already indexed.
Number of Suggestions

When searches return 0 results Search Boost can be configured to give hints to the users that would actually return results. The number of hints can be configured through this option. Setting it to 0 will disable suggestions.
The way it works, Search Boost builds a second index with all the words and runs a special spell check plugin that returns similar terms. These terms are surely to bring results because they were added there from the main indexed content.
One thing to note is that the lower is the Fuzzy Search similarity, the less likely this option will be visible because searches will automatically match similar terms from the start.
Enable More Like This

When this option is enabled, each result will have a “More Like This” link that when clicked returns simillar results based on the selected number of repeated terms. If the Contextual Highlight is enabled, you will see which words have been considered. For a words to be considered it must appear N times inside the content of the original result. Common words configured with the Stop Words option described later in this section will be ignored.
Fuzzy Search
This feature refers to the ability to return results even when the words don’t match 100%. For example, searching for “test” will also bring results that contain “text” when the similarity index (configured in administration console) is less than 75%.
This option is specified as a similarity percent, where 100% will disable the Fuzzy Search. Internally, this works by calculating the Levenshtein Distance, which is a measure of similarity between two strings. The distance is measured as the number of character deletions, insertions, or substitutions required to transform one string to the other string.
This is very powerful feature but we’re also planning additional features around this like language corrections, auto suggestions and stemming.
WildCard(*) Search
The smallest part Search Boost normally searches is the word. Enable this option to have Search Boost also match the input that appears as part of words. For example, searching for *st will return results containing words that end in st such as boost.
The wild card character can appear at end or inside of search terms, it can’t be the first character. By choosing the implicite option users no longer have to type the asterisx character, it will be appended automatically by Search Boost at the end of search terms.
Note that wildcard search is not compatible with the Highlighter or Stem Filter!
Multi Word Searches

Define standard behavior when the search contains more than one word.
The behavior is defined as a logical operation that determine which results are considered based on how the search term appear inside content. Available options are:
- ANY - It will match results that contain any of the words
- ALL - It will match results that contain all of the words
- EXACT - It will match results that contain the exact phrase (using the specified Slop index) Note that exact match is still possible in all cases by enclosing the words in double quotes.
Highlight Search Terms in Results

Search Boost can highlight the search terms within search results to make content easier to locate. But it’s more than this, because first of all the engine tries to build the description so it contains as most of the search terms as possible. This makes it a very useful and friendly feature. When this option is enabled any description you used to build the search items will be ignored.
Note that the highlight style can be changed from the template by modifying class “highlight”.
The slop defines how close to each other the words from the exact search phrase need to be in order for it to be considered a match. For example, searching for “quick fox” will match text “the quick brown fox” only when the slop is greater than or equal to 1 because the “brown” word is in between.
Change the value of this option to define the tolerance to noise of the exact phrase search feature. The higher this index is, the more words can exist between the exact phrase search. Note that words configured with the Stop Words feature are not counted.
If this option is disabled, Search Boost no longers matches keywords in the content. Use this to create for example a ‘search titles only’ function.
Search Additional Fields
Normally, only the content is searchable. For an HTML module this means the text you typed in and for a document it means the text from the document. But it’s possible to instruct Search Boost to search additional fields, such as the titles (module titles, document titles, etc), descriptions, folder names and so on.
Not all documents and fields are created equal - or at least you can make sure that’s the case by using boosting. Each of the additional fields can be configured with a boost. What this does is define how important is when a search term appears in the field. It’s natural for example that if a search term appears in the title of a module, it’s considered more important than when same word appears inside the content.
Note that the boost is not an absolute value. It aggregates with other boost factors to produce the final relevance index. Other factors include:
-
How big the content is - the shorter the content of the field the more important that field is considered to be, so for example if the content is smaller than the title the search engine will consider the content to be more important.
-
How many times the word appears in given field - the more a word appears in a field, the more important is considered to be
-
Other boost factors defined using Search Boost features - for example, in the Metadata of documents or using the Boost Recent Documents feature described below
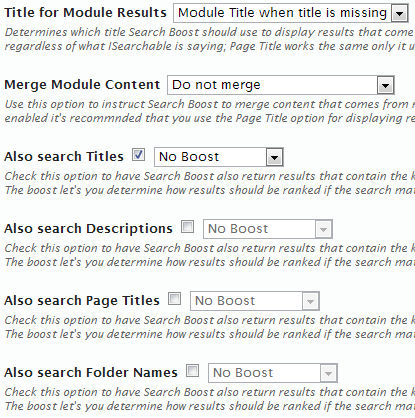
Title for Module Results
This option determines which title Search Boost should use to display results that come from modules.
- Module Title means Search Boost will always use the title of the module regardless of what ISearchable is saying.
- Page Title works the same only it uses the page title (or if not specified it uses the page name).
- Module Title when title is missing means that whenever you use a module with more items like a blog creating module (e.g. Easy DNN News) and one item (article) does not have a title, then, Search Boost Results will display the title of the module.
- Page Title when title is missing means that whenever you use a module with more items like a blog creating module (e.g. Easy DNN News) and one item (article) does not have a title, then, Search Boost Results will display the title of the page.
Merge Module Content
With this option you to instruct Search Boost to merge content that comes from module son the same page to prevent duplicate results. Note that if this option is enabled it’s recommnded that you use the Page Title option for displaying result titles.
Also Search Page Titles
This option allows to have Search Boost also return results that contain the keywords in titles.The boost let’s you determine how results should be ranked if the search matches this field.
Also Search Descriptions
Check this option to have Search Boost also return results that contain the keywords in descriptions.The boost let’s you determine how results should be ranked if the search matches this field.
Also Search Page Titles
Check this option to have Search Boost also return results that contain the keywords in page titles.The boost let’s you determine how results should be ranked if the search matches this field.
Also Search Folder Names
Check this option to have Search Boost also return results that contain the keywords in folder names.The boost let’s you determine how results should be ranked if the search matches this field.
Boost Recent Documents
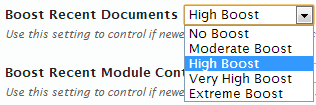
With this setting you can control if newer documents should be considered more relevant and therefore rank higher within results. In this case Search Boost uses the last modified date of the document.
Boost Recent Module Content
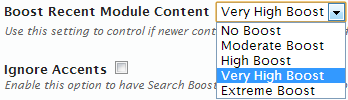
This setting allows you to control if newer content from modules should be considered more relevant and therefore rank higher within results. Search Boost uses the last modified date reported through the ISearchable interface.
Note that many modules don’t return real values for this so this boosting may not be entirely accurately.
If you want to find out more on how boost works, check out this article explaining how scoring is calculated in Lucene: www.lucenetutorial.com/advanced-topics/scoring.html.
Ignore Accents

Enable this option to have Search Boost ignore accents so all word are searchable using standard Latin characters. This setting is global (for all instances). For example, when this option is enabled, searching for Corazón will return same results as searching for Corazon.
Internally this is achieved by converting the accents to their Latin equivalents both in the search index and in the search terms. This setting is global (for all instances).
Stop Words

This options allows building a list of words that the Search Engine will ignore from all operations. These include searching, calculating phrase slops, suggestions, exact match searches, more like this searches and so on.
In this list put words such as common words (“and”, “or”, etc), profanity words or anything you consider not to be relevant to a search. You need ot specify one word per line.
Note that the default list is of English words, but you can extend or change that with any list of words you want. In a future release we’ll make Search Boost multi-language, then this list will be per locale.
This setting is global (for all instances).
Word Splitting Characters

This option determines how the text is split into words.
Use Stemming (English Only)
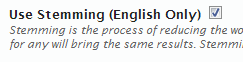
Stemming is the process of reducing the word to a base form. For example, stemming will make “search”, “searches”, “seaching”, “searched” identical, so a search for any will bring the same results. Stemming only works for English words and requires Search Boost Analyzer in General Settings.