Architecture
In version 3.0 we’ve made major changes to architecture in order to allow for better scalability and extensibility.
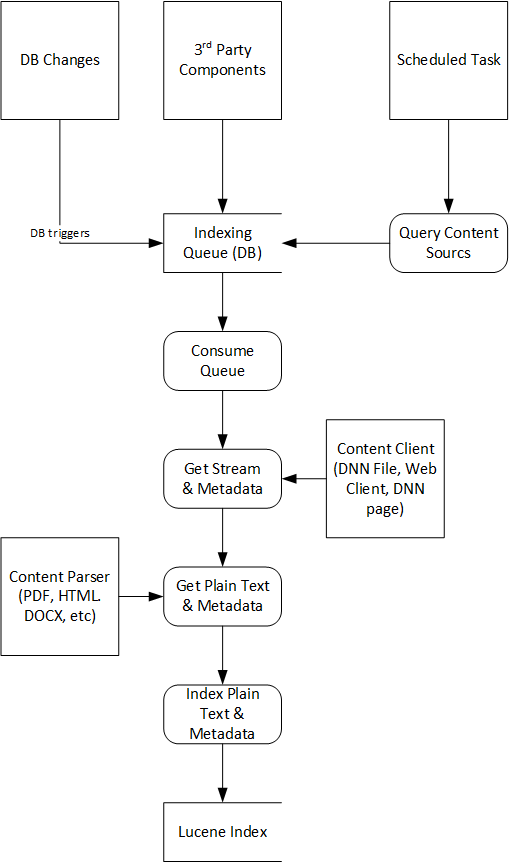
Content Sources
Content sources generate content that needs to be indexed, for example modules, custom rules, files, URLs and so on. The Search Boost scheduled job loads all content sources defined in configuration files and queries them for content. The content sources can either respond with the content to get indexed, or send back an ID. In either case, the content is pushed to a Indexing Queue. Another scheduled job, called Search Boost Indexer, consumes this queue. Real Time Indexing
Real time indexing means that new contents will appear instantly in search results. This is an ideal situation for a search engine. External search engines such as Google have a hard time doing that because the website doesn’t notify the search engine when new content is available. But with Search Boost, many changes can be observed real time with database triggers, file monitors or other event listeners. All of these components will push data to the Indexing Queue.
Indexing Service
This is a scheduled job that runs by default every 5 seconds and queries the Indexing Queue for new content. It consumes the queue in batches in order to avoid blocking the website with too much processing. For each item in the queue, if the content is not already there, Search Boost will try to identify a content source that can retrieve the content by its ID, and then a content parser that is capable of extracting the plain text and metadata from content.
Content Clients
A Content Client is a component responsible to pull content from a source knowing it’s unique ID. Most common example is to retrieve web content by knowing the URL. The content can be an HTML page, or can be a binary file (for example a PDF). It’s returned as a generic bit stream. Next in the pipeline, Search Boost will call a Content Parser to extract the content from that stream.
Content Parsers
A content parser is responsible for extracting plain text and metadata from a stream retrieved from a Content Client. Common examples are the PDF parser or HTML parser.
Metadata
Ultimately what gets indexed in plain text content - for example the content retrieved for a module. But besides content, there’s also metadata, which add more information about the content. For example, a module would also provide a Title and permissions related to the content. In this example, the metadata is supplied by the content source, but it can easily be provided or completed by Content Clients and Content Parsers as well. For a Content client, think of the Web Client that along with the stream also receives HTTP headers that would specify the last modified date of the content. For a Content Parser, imagine an HTML parser where it will extract the title and keywords from the corresponding HTML tags.