Debug Index
The need for Lucene Search Engine
Starting with version 2.0 Search Boost works exclusively with own indexing engine based on Lucene.NET. This gives us full control so we can overcome all limitations in DNN Search design. This is a good things as it results in faster, more accurate and powerful searches. Read more about Limitations of DNN Search on how Search Boost overcame them.
Unlike the standard search store from DNN which saves the index in Database, Lucene saves it on disk. This is saved under \Portals\{portal id}\Cache\SearchBoost\{instance id}\SearchIndex folder.
Note that saving the index on disk has a few notable advantages compared to the database because of:
-
Scalability. Simply put, MS SQL doesn’t scale (at least not horizontally across multiple machines). The disk storage these days is extremely scalable and Lucene also supports reading indexes from multiple locations (although Search Boost doesn’t support this for now)
-
Deployment / Backups. It’s a lot easier to copy files than to copy database content.
-
Faster Access. Lucene database was especially designed for storing indexed content for the purpose of searching it. A MSSQL database is a generic relational structure with a lot of overhead in terms of security, transactions and integrity checks. The highlights above relate only to the storage structure and not the features. Lucene is a lot more powerful than DNN Search and comes with features such as fuzzy search, phrase search, advanced search syntax and so on.
Check that Search Boost “sees” your files as expected
Besides indexing plain content from modules, databases or web pages, Search Boost can also index documents that are binary files. This means that there are special libraries designated with reading and translating these binary files to plain text that can afterwards be indexed and searched.
Either these libraries function correctly or not is one of the biggest cause of debugging we receive at support. Let’s take for example PDFs. There are many server configurations having or not having IFilters installed or the PDF Box Extension we have available for download. And there are many standard of PDFs, some have plain text in them, some have the text encoded in glyphs, some are scanned assets and so on. To support all of them is impossible, but the aim is to support most of them.
For this purpose we created a test script that allows you to upload a file and it will show you what text can Search Boost extract from that document. Use this to see that the document indexers work correctly, or to try various configurations. For example, if PDFs don’t index nice, then you can try to install the PDF Box extension and give it another try. If still no go, you can uninstall the extension, install another IFilter package and try again. Without the script below this would be difficult as you would have to reindex the whole content between tests to make sure index is up-to-date.
To test document indexers:
-
Open you portal at
//yoursite/DesktopModules/DnnSharp/SearchBoost/TestDocIndexer.aspxIf you’re not logged in, you’ll be asked to do so before being able to do the tests -
Use the Browse Button to locate the file you want to test and hit Extract Content.
-
If the document has been recognized properly, you should see its plain contents in the text area below the upload field
-
If you don’t see the content you expect, or you see an error, please contact us for support. But before that, make sure that for PDFs you also try the PDF Box extension downloadable from our site. And for other document types, make sure you have appropriate IFilter packages installed.
Analyze Lucene Index with Luke
Luke is a Java application capable of opening the index and do all sort of simple or advanced queries that are supported by Lucene. You can read more about luke and download it at code.google.com/p/luke.
When you open Luke it will ask for the indexing folder. Locate the folder \Portals\{portal id}\Cache\SearchBoost\{instance id}\SearchIndex{largest number}.
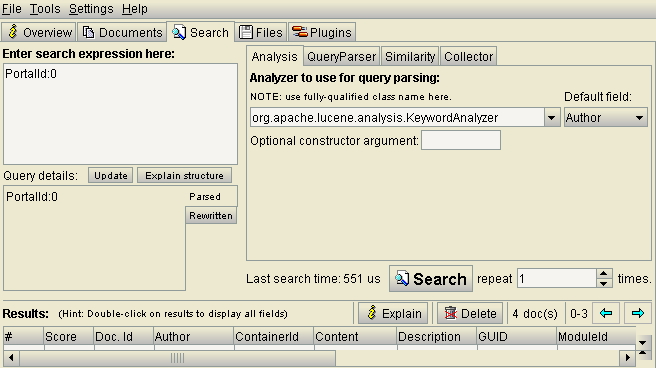
The simplest thing you can do is to see all content indexed for a portal. Go to Search tab, and type PortalId:0 in the search box then hit the Search button. There are arrows to navigate between result pages.
In Luke you can use the full search syntax of Lucene which is not available in Search Boost (but you can create one with DNN Sharp Advanced Search). For a quick help read about Query Parser Syntax.
Note that Lucene is very complex and requires some reading before mastering it. Normally you don’t need to do this because Search Boost takes care of everything unless you’re interested to know how things work under the hood or determine how the contend could be better searched and ask us to implement some features. For a comprehensive reading we recommend Lucene in Action, Second Edition.
Submit Debug Information for Further Investigation
If your search does not behave as you’d expect please contact us for support. We’ll most likely need you to do the following in order to have a complete view of the issue:
-
Go to Search Boost -> General Settings -> Advanced Settings and set both loggers to Debug then save settings.
-
Click Clear Index and wait for success message. This only wipes the Search Index, which is a database located under
\Portals\0\Cache\SearchBoost\{instance id}\SearchIndex\ folder. -
Click Index Content and wait for success message.
-
Go back to the site and search for something you know it should bring results. You could also use the Test Search, but that uses slightly different code so not all steps would be visible.
- Download debug information
- Send the zip archive to us via email (or setup a place where we can download it if it’s too big)